Problem
When building AI systems, choosing a model is rarely straightforward.
Different providers behave differently under the same task. Some are accurate but expensive. Others are cheap but unreliable. These differences are often discovered late, through trial and error.
Evaluation is usually external to the system. Models are integrated first, then tested. This makes behaviour difficult to reason about in a consistent way.
This work treats evaluation as part of the system itself.
System Overview

This note examines the evaluation layer of a broader AI platform system.
Supports both API-based and local models through a unified interface. The same task can be executed across providers and compared under controlled conditions.
The objective is to make model behaviour observable during system execution, rather than after integration.
System Architecture and Design Choices
The system is structured around separation of concerns.
The codebase is organised into four components:
- runtime_gateway: inference and API exposure
- orchestration_engine: structured execution
- eval_engine: benchmarks and experiment execution
- shared: providers, schemas, and common abstractions
Each layer serves a distinct role. Runtime handles serving. Orchestration defines execution flow. Evaluation handles measurement.
A key design decision is the provider abstraction. All models implement a common interface, allowing tasks to be executed across providers without changing system logic.
Evaluation is embedded into the system. Benchmarks are defined as configuration and executed through the same runtime path. This ensures consistency and reproducibility.
The system also separates control from execution. Experiments are triggered via CLI, while inference is exposed through an API. This reflects how evaluation and serving are handled in production systems.
Method
Two benchmarks are used.
The QA benchmark tests factual responses using short-answer questions. The instruction benchmark tests constraint following, such as formatting and limited outputs.
Evaluation checks for expected output presence in the response, providing a consistent baseline for behaviour comparison.
Experiments are defined through configuration, making them reproducible.
What I Observed
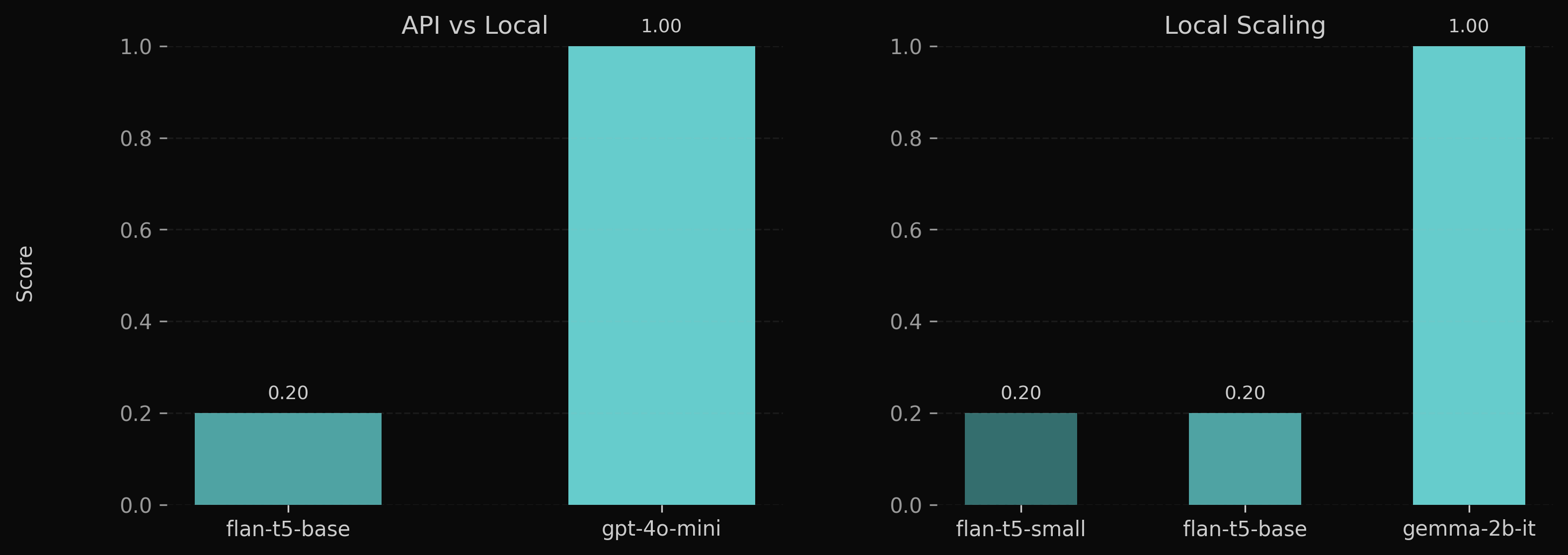
Model behaviour evolves in stages.
At small scales, local models fail to produce stable outputs. Responses are often incoherent or unrelated to the input.
Increasing model size improves structure. Outputs become well-formed and follow expected patterns, but correctness remains inconsistent.
A qualitative shift occurs with a sufficiently scaled and instruction-aligned model. Responses become both structured and correct.
This progression shows that structure emerges before correctness. Reliable correctness requires both scale and alignment.
API models operate in this regime by default. Smaller local models do not.
Fair Comparison
A direct comparison between a strong local model and an API model shows no difference on this benchmark. Both produce correct and well-formed outputs.
This indicates that the earlier gap is not inherent to local models, but a function of scale and alignment.
The difference lies in consistency. API systems operate reliably at this level across tasks. Local models require careful selection and configuration to reach similar behaviour.
System Insight
Model behaviour is not binary. It evolves.
At small scales, models fail to produce stable outputs. With increased capacity, structure emerges. Correctness follows only when models are sufficiently scaled and instruction-aligned.
This progression explains the gap between local models and production systems. The difference is not access to knowledge, but consistency of behaviour under constraints.
Evaluation therefore cannot be external. If a system depends on multiple models, it must measure how they behave under identical conditions.
Conclusion
This approach makes model behaviour observable within system execution.
Instead of selecting models by assumption, behaviour is measured, compared, and understood as part of the system itself. This enables informed decisions about model selection, routing, and deployment trade-offs.